Putting the Swarm to Work II
Righting the wrong
I though my last try was a failure, but I was wrong. I discovered the day after writing my last post, that the “missing” records were being displayed, so it was a matter of timezone misconfiguration. After checking every component of the swarm deployment and ensuring all were correctly configured to use UTC, I turned to my log injector.
It was a docker container running nxlog directly on my computer which was sending the records without timezone indication (bsd syslog) using the local timezone. Once it was configured to use UTC and timezone indication to_syslog_ietf() the records were shown as they came on the search console.
Going back to work
It’s been 20 days since my previous post, some family business prevented me to work on my home lab during my spare time, but fortunately the company I work for, S2 Grupo, was interested of deploying graylog and elasticsearch using dockers and I was able to borrow a little time to work on it from my working time. So I could said this post was partially funded by S2 Grupo.
Leveraging the work with Ansible
Knowning how to manually deploy a compose file to the swarm is a basic skill while working with docker swarm, but in order to do it in a more repeatable way, I looked for the way to do it using ansible.
I found the ansible module community.docker.docker_stack which allowed me to deploy my compose file into the swarm.
- name: Deploy compose into swarm
community.docker.docker_stack:
state: present
name: "{{ glstackdeploy_stack_name }}"
compose:
- "{{ glstackdeploy_base_dir }}/glstackdeploy.yml"
run_once: yes
tags: deployCompose
As my deployment required several configuration files and several preconfigured tasks, I decided to write a role, which I plan to share on ansible galaxy in a near future, it’s available from my github homelab repo for now.
juanjovlc.glstackdeploy/
├── defaults
│ └── main.yml
├── files
│ └── default-inputs.json
├── README.md
├── tasks
│ └── main.yml
└── templates
├── glstackdeploy.yml.j2
├── graylog.conf.j2
├── haproxy.cfg.j2
├── init-replicaset.sh.j2
└── rsyslog.conf.j2
It creates the configuration files for graylog, syslog and haproxy, the compose file glstackdeploy.yml, copies the mongodb’s init script and deploys the stack to the swarm.
I also made a small improvement on atosatto’s swarm role, to make it capable of using values on node’s tags.
--- a/atosatto.docker-swarm/tasks/setup-swarm-labels.yml 2020-05-08 13:29:54.000000000 +0200
+++ b/atosatto.docker-swarm/tasks/setup-swarm-labels.yml 2021-07-05 12:34:52.154417585 +0200
@@ -22,7 +22,7 @@
- swarm_labels
- name: Assign labels to swarm nodes if any.
- command: docker node update --label-add {{ item }}=true {{ ansible_fqdn|lower }}
+ command: docker node update --label-add {{ (item.find('=') > 0) | ternary( item , item ~ "=true") }} {{ ansible_fqdn|lower }}
when: item not in docker_swarm_labels.stdout_lines
with_items:
- "{{ swarm_labels | default([]) }}"
That change allowed me to label the swarm nodes exactly as I needed to place constraints on container’s deployment.
[docker_engine]
node1 swarm_labels='["mongo.replica=1", "esmaster", "glmaster"]'
node2 swarm_labels='["mongo.replica=2", "esmaster", "glslave"]'
node3 swarm_labels='["mongo.replica=3", "esmaster", "glslave"]'
node4 swarm_labels='["esdata=hot", "glslave"]'
node5 swarm_labels='["esdata=hot", "glslave"]'
node6 swarm_labels='["esdata=warm", "glslave"]'
node7 swarm_labels='["esdata=warm", "glslave"]'
I took advantage of Jinja2 templating and made not only the compose file, but also the configuration files dynamic, using conditional blocks, for loops, and variables.
haproxy.cfg
...
listen graylog
mode tcp
bind *:12200-12300
balance roundrobin
option tcplog
option log-health-checks
option logasap
option httpchk GET /api/system/lbstatus
{% for host in groups['glslave'] %}
server gls-{{ host }} gls-{{ host }} check port 9000 resolvers docker init-addr libc,none
{% endfor %}
...
glstackdeploy.yml (compose file)
...
{% if glstackdeploy_deploy_cerebro %}
cerebro:
image: juanjovlc2/cerebro:latest
environment:
- "CEREBRO_BASE_PATH=/cerebro/"
- "CEREBRO_PORT=8000"
networks:
- {{ glstackdeploy_network_name }}
{% endif %}
...
One tricky part was using golang templating on docker configs, because it collided with jinja2 templating for ansible because of the double curly braces {{ }} used in both engines. The solution was turning the golang braces into jinja interpolated strings:
x-eslasticsearch-common: &escommon
image: docker.elastic.co/elasticsearch/elasticsearch:{{ glstackdeploy_es_version }}
hostname: esdata-{{ '{{' }} .Node.Hostname {{ '}}' }}
volumes:
- {{ glstackdeploy_data_dir }}/elasticsearch:/usr/share/elasticsearch/data:z
configs:
- source: escert
target: /usr/share/elasticsearch/config/escert.crt
mode: 0444
- source: escertkey
target: /usr/share/elasticsearch/config/escert.key
mode: 0444
networks:
- {{ glstackdeploy_network_name }}
Initializing the mongo’s replica set was also tricky, as I was not exposing the mongodb port, I wasn’t able of using ansible.builtin.wait_for, so I put a timer and the initializing task on a block, tagged it with the never tag and I only used it when I was initializing the stack for the first time using --tags=all,never.
- name: Mongodb init block
block:
- name: Pause for 60s, waiting for mongo to start
pause:
prompt: Giving time mongo1 to start
seconds: 60
- name: Call init script
shell:
cmd: "{{ glstackdeploy_base_dir }}/scripts/init-replicaset.sh"
register: initoutput
tags: never
- name: View init output
debug:
var: initoutput.stdout_lines
when: initoutput is defined
run_once: yes
delegate_to: node1
tags: never
Please, note I also tagged the play which invoked the role as deployStack in order to run only that part.
- name: Deploy stack
tags: deployStack
hosts: docker_swarm_manager
roles:
- juanjovlc.glstackdeploy
But that made the effective tags of the initializing block [deployStack, never] so the block was called when using --tags=deployStack. In order to prevent the initializing block for running when running the playbook with the given tag, the following command should be used:
ansible-playbook site.yml --tags=deployStack --exclude-tags=never
Conclusion
Though this work is not production ready, for me, it’s progress. A month ago I knew nothing about docker swarm (I admit, I knew it existed), and now I’m deploying 32 containers with a simple ansible playbook.
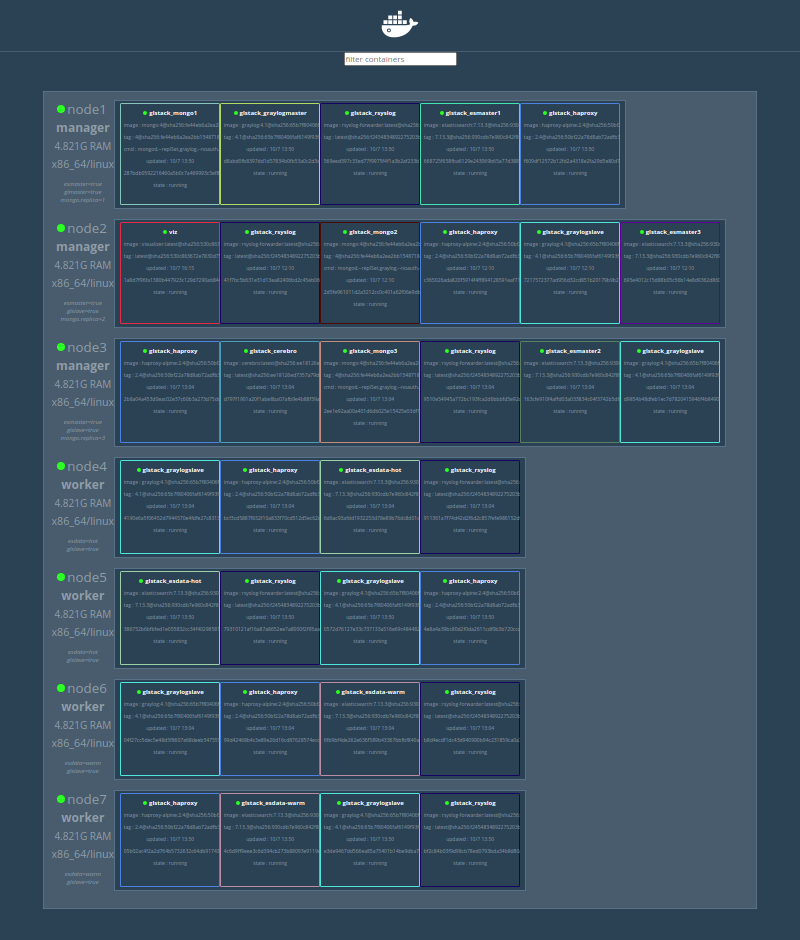
Captured used dockersamples visualizer
I can even image committing an inventory file and having a CI/CD pipeline running the playbook, but the day I’m capable of doing that, it’d mean I made myself redundant.
References
The relevant files are on my homelab repo
Next steps
The following steps should be.
- Tidying up the role: more variables, customized volumes, etc.
- Test record ingestion performance.
- Check for unwanted East-West traffic
- Contrib patches to atosatto’s roles