Graylog Fake ES Federation
Currently I’m working with big data sets on Graylog + Elastisearch deployments, it runs smoothly when everything is fine, but dealing with backups/snapshots and maintenance tasks is complicated. We were thinking of several solutions using the features already available on ES.
The goal was having several tiers of indices to extend data retention chaining several clusters.
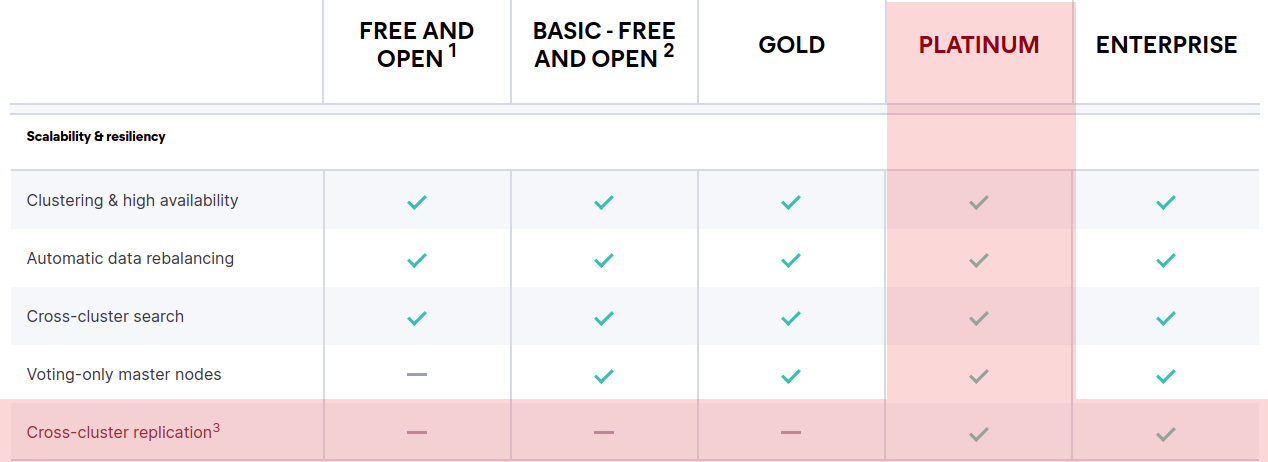
Cross Cluster Replication
Elasticsearch provides an awesome feature called Cross Cluster Replication, it allows follower clusters to automatically replicate the leader cluster, this feature allows using the classical “one database for writing, several replicas for reading” approach to increase application’s performance.
This coupled with Cross Cluster Search brings the opportunity of having those replicas isolated or hidden, as there is no need of accessing them directly.
But unfortunately cross cluster search is nowhere in Graylog’s plans, and, the other big issue, is although cross cluster search is free, cross cluster replication isn’t.
Poor man’s ES replication
Another option ES provides are snapshots, and that’s the recommended method for data migration between clusters. But it requires a shared storage between clusters, and that would be a third copy of your data. This method is well documented on Elastic’s website, so I’m not going to test it.
I tried another ES feature, reindexing from remote cluster.
The steps were simple:
- Whitelisting some source nodes on the destination cluster. This is a non-dynamic setting, so I had to restart the nodes (almost one).
echo reindex.remote.whitelist=source1:9200,source2:9200 >> elasticsearch.yml && systemctl restart elasticsearch
Note: use your configured http.port (defaults to 9200)
For the following steps I used an script
- Create the destination index without replicas to speed up copying.
- Issue the remote reindex command.
- Block the index for writings and enable replicas.
The script I used was:
#!/bin/bash -x
ESSOURCE="http://sourcenode:9200"
ESDEST="http://destnode:9200"
for i in {0..1}; do
curl -v -XGET $ESSOURCE/graylog_$i |jq .graylog_$i |jq 'del(.settings.index.blocks, .settings.index.version, .settings.index.uuid, .settings.index.provided_name, .settings.index.creation_date) | .settings.index.number_of_shards=2 | .settings.index.number_of_replicas=0' |tee graylog_$i.json | curl -XPUT -d @/dev/stdin -H "Content-type: application/json" $ESDEST/graylog_$i
cat <<EOF | curl -XPOST "$ESDEST/_reindex?pretty" -H 'Content-Type: application/json' -d@/dev/stdin
{
"source": {
"remote": {
"host": "$ESSOURCE"
},
"index": "graylog_$i"
},
"dest": {
"index": "graylog_$i"
}
}
EOF
curl -XPUT "$ESDEST/graylog_$i/_settings" -d '
{
"index": {
"blocks" : {
"write" : "true",
"metadata" : "false",
"read" : "false"
},
"number_of_replicas": 1
}
}'
done
As I wanted to preserve all the settings and mappings I got the index’s settings from source, and used jq to strip the settings that are not allowed at index creation, and to adjust the number of shards to the destination cluster setup, and remove replicas.
Graylog interface
As graylog itself don’t allow federation, I set up an additional graylog server, but pointing to the destination cluster.
My first try was adding that second graylog to the existing cluster, using the same mongo database, it seemed to be working, but with some misbehavior, for instance, the indices and their range changed depending on which node performed the range calculation.
So I had to move the graylog accessing the replica to a new mongo database. It worked, the ranges were not longer been overwritten depending on which node calculates them, but I miss all inputs and streams I had set up on the source node, but searching worked. The best approach to keep everything synchronized is exporting content-packs from the source graylog and importing them on the replica, because stream ids and inputs ids are preserved, the information will be coherent.
Suggestions
As this is a not standard configuration, I had to perform some actions in order to keep it running:
- In order to prevent the secondary Graylog to write in the newly created indices as they were being replicated, I created an empty index with a very high number:
graylog_9999, then graylog automatically pointed thegraylog_deflectoralias to this index. - I set up the index retention configuration to ‘Do nothing’ in both graylogs, so I could be sure indices were replicated before deletion. It’s recommended using graylog’s API to delete replicated indices, becasue the ranges are also updated this way, using elasticsearch interface will require calling range rebuilding manually on graylog.
- I hadn’t found a way to make graylog notify index rotation, so checking periodically for new indices is required.